Kimi K2.6: Open-Weight 1T Agent Model You Can Actually Run
Moonshot AI's trillion-parameter MoE with 256K context and a 300-agent Swarm mode. Benchmarks, hardware requirements, and who should actually self-host it.

Kimi K2.6: an open-weight 1T-parameter agent model you can actually run yourself
Moonshot AI dropped a trillion-parameter MoE with 256K context and a Swarm mode that runs 300 agents for 12 hours straight. Here's what matters for builders.
Moonshot shipped Kimi K2.6 on April 20, 2026 — and unlike every "open-source" LLM release in the last year, this one is actually useful if you care about agents, not just chatbots.
I spent the morning reading the model card, watching teardown threads, and pulling the weights from Hugging Face. The TL;DR: it's the first open-weight model where the multi-step agent story is competitive with Opus and GPT-5. The pure single-turn reasoning still trails. Whether that matters to you depends entirely on what you actually build.
What's actually under the hood
The architecture is a Mixture-of-Experts, which means the 1 trillion parameters are just the storage cost. At inference time, only 32 billion wake up per token — the rest stay dormant. That's the trick that makes it runnable at all.
- 384 experts total — 8 routed per token, 1 shared that always fires
- Multi-head Latent Attention (MLA) — the same approach DeepSeek used, cuts KV-cache memory hard
- SwiGLU activations, MuonClip optimizer — nothing exotic, just battle-tested parts
- Native INT4 — they trained with Quantization-Aware Training from the start, so the 4-bit version isn't a downgrade, it is the model
Weight file sits at roughly 594 GB. That's not a typo. You're not running this on your MacBook.

On a pair of H100s you won't run this. Full production needs 8× H100 or H200 GPUs. A cut-down INT4 variant fits on 4× H100 with reduced context. Consumer hardware? You'll see 1–7 tokens/sec — technically working, practically useless.
Four variants — and why Swarm is the headline
Moonshot isn't shipping one model. They're shipping four modes, each tuned for a different workload. Same base weights, different runtime behaviour.
Single-turn responses, no chain-of-thought overhead. When you need answers in milliseconds, not minutes.
Full CoT with a configurable reasoning budget. For problems where you'd rather wait 30 seconds and get it right.
Executes tasks autonomously with tool access. Loops, retries, plans. The ChatGPT-Agent / Claude-Code tier.
Up to 300 parallel sub-agents, 4,000 coordinated steps, and runs lasting 12+ hours. Overnight shift in a box.
Swarm is the interesting one. If you've ever watched a single-agent loop choke on a migration because it can't hold the whole codebase in context, this is the answer — you fan out into 300 subprocesses, each with its own slice, and the orchestrator stitches the result back together.
What's new vs K2.5 (and why it matters)
K2.6 isn't a new architecture — it's K2.5 with better post-training. But the deltas are where the story is:
| Capability | K2.5 | K2.6 |
|---|---|---|
| Parallel sub-agents | 100 | 300 |
| Max tool-call steps | 1,500 | 4,000 |
| Native video input | — | mp4, mov, avi, webm |
| Long-context stability | Degrades past 128K | Holds through 256K |
| WebGL / shader output | Text only | Animations + shaders |

The native-video bit gets overlooked in the discourse but it's a real unlock. No more transcribing → chunking → feeding text. Drop an mp4 in, get a reasoned response. Up to roughly 2K resolution recommended.
Benchmarks — read between the lines
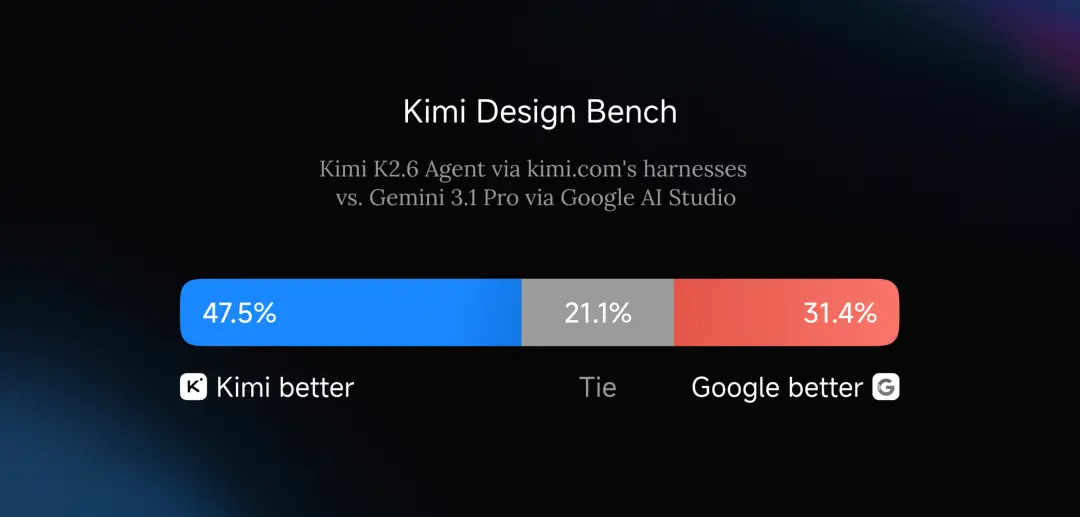
Every model release comes with a benchmark deck that shows it winning. K2.6 is no exception. But if you squint at which benchmarks they picked, the story gets honest.
Where K2.6 holds its own
- SWE-Bench Pro — agentic coding tasks. Competitive with Claude Opus 4.6.
- BrowseComp — browsing + research. In the same ballpark as GPT-5.4.
- HLE (Humanity's Last Exam) — long-horizon tool use. Strong showing.
Where it still trails
- AIME — competition math. GPT-5.4 and Gemini 3.1 Pro are ahead.
- GPQA Diamond — PhD-level science Q&A. Same gap.
Translation: if your workflow is "give the model a task and let it do things for hours," K2.6 is in the conversation. If you're running it as a pure reasoner on hard problems, the closed models still win on the hardest slices.
All launch-day benchmarks are self-reported by Moonshot. Independent third-party evals (LMSYS, Scale, HELM) will land in the next few weeks. Treat the numbers as directionally right, not gospel.

Can you actually run it?
Depends who "you" is. Three scenarios:
You have a real GPU cluster
Pull the weights from moonshotai/Kimi-K2.6 on Hugging Face. Moonshot recommends vLLM 0.19.1 in production — also supports SGLang and their proprietary KTransformers engine. On 8× H100 you'll get usable throughput. On 8× H200 it sings.
# Production deploy on 8× H100
vllm serve moonshotai/Kimi-K2.6 \
--tensor-parallel-size 8 \
--max-model-len 262144 \
--quantization int4You want to use it via API
Paid per-token access via platform.moonshot.ai. Pricing undercuts the equivalent Claude / GPT tiers by a meaningful margin — which is the real business angle. If you're burning $5K/mo on Opus for agent workflows, K2.6 Agent via their API is worth a price check.
You just want to try it
Go to kimi.com, free with usage limits. Zero setup, and you get the same model quality. Subscription tiers unlock heavier use.
The license, and who should actually pay attention
Modified MIT — meaning: do whatever you want, attribution not required, until you cross 100M monthly active users or $20M monthly revenue. Above those thresholds you owe Moonshot attribution. Not payment. Just credit.
For 99.99% of teams reading this, it's effectively an unrestricted commercial license. That's a bigger deal than it sounds. Most "open-source" model licenses have acceptable-use clauses that read like a minefield.

Who should care
- Anyone doing long-horizon agent work — code migrations, research pipelines, batch automation that needs 12-hour runs
- Regulated industries — healthcare, finance, defence, anyone with data that can't leave the building
- Teams burning serious spend on agent APIs — if your Opus bill has three commas, run the numbers on self-hosting
- Non-US companies with data sovereignty rules that rule out Anthropic / OpenAI
Who shouldn't bother
- Solo builders running things on laptops — you don't have the hardware and the API is cheaper than your electricity bill for a home rig
- Anyone whose workload is mostly single-turn chat — Haiku 4.5 is faster and cheaper
- Teams in security-sensitive US gov work — geopolitical risk of a Chinese-origin model will get you blocked in procurement
What's still missing
I'd be lying if I called this production-perfect out of the gate. The honest caveats:
- "Claw Groups" — Moonshot's human-in-the-loop feature — is still in research preview. Don't plan production workflows around it yet.
- Ecosystem tooling is thin. LangChain, LlamaIndex, and most agent frameworks will need adapter patches. Give it 30 days.
- Fine-tuning guides aren't published. If you need domain-specific tuning, you're on your own with vanilla LoRA approaches.
- Kimi K3 rumours (3–4T parameters) are floating around unsourced Twitter threads. No official roadmap yet. Take it with a shaker of salt.
The bottom line
K2.6 is the first open-weight model where I'd seriously consider replacing a closed-model agent workflow. Not for reasoning. For doing.
→ Use it if
- You run multi-hour agent pipelines
- You need data to stay on-prem
- Your Opus/GPT-5 bill is 5 figures monthly
- You ship code migrations, batch research, or infra automation
→ Skip it if
- You don't have 8× H100 access or budget for it
- Your workload is chat + single-turn reasoning
- Regulatory or procurement blocks Chinese-origin models
- You'd rather pay the closed-model premium for polish
What to do next
Three concrete moves, from zero effort to full send:
- Free path: open kimi.com, paste in your hardest agent prompt, see how it compares to what you use now. 10 minutes.
- API path: sign up at platform.moonshot.ai, wire K2.6 Agent into one workflow you currently run on Opus, measure quality + cost delta for a week.
- Self-host path: if the API numbers look good and your compliance team cares, spin up the INT4 variant on a 4× H100 box and benchmark it against your production workloads before committing to full 8× infra.
Open weights matter less when they're worse than closed. K2.6 is the first one I've seen where "worse" is a real argument rather than a foregone conclusion. Play with it this week — either it's in your stack by month-end, or it isn't, but you shouldn't be guessing.
If you're building agents and want the playbooks, workflows and templates I actually use — that's what Knox Community is for. Free builder content on the hub, deeper stuff behind the Skool door.
Frequently Asked Questions
What is Kimi K2.6 and who made it?
How does Kimi K2.6 compare to Claude Opus 4.6 and GPT-5.4?
What hardware do you need to run Kimi K2.6?
Is Kimi K2.6 free to use commercially?
What's the difference between K2.6 Instant, Thinking, Agent, and Agent Swarm?

Want more like this?
Join Knox community — templates, live sessions, and a network of builders.
Comments
Loading comments...
Published April 21, 2026
Building businesses with automation and AI. Sharing workflows, templates, and real strategies that work.
Related content

Claude in Chrome: Setup Guide + 6 Workflows You'll Actually Use
How to install Claude in Chrome, connect it to Claude Desktop and Claude Code, and start automating real browser workflows in under 10 minutes.
guide
How to Stop Re-Explaining Yourself to Claude Every Day
I spent three weeks typing the same brand instructions into Claude every morning before I did any actual work. Skills fixed that in one afternoon. Here's the setup that actually sticks.
guide
Magic MCP Turns Claude Code Into a UI Designer
Claude Code's default output is gray boxes and Arial. No animations, no hover states, nothing. Magic MCP fixes that — one command, and you're getting gradient text, glow cards, and Framer Motion out of the box.
guide